基于 ShuffleNetV2 的图像分类
1. 配置 Docker 开发环境
参考 这里 配置好 Docker 开发环境后,再回到这里继续下一步
若您使用已经配置好的 Docker 开发环境,请您启动 Docker 后务必按照 Docker 配置教程执行 source ./tpu-mlir/envsetup.sh 命令,否则后续步骤可能报错。
2. 在 Docker 中准备工作目录
创建并进入 shufflenet_v2 工作目录,注意是与 tpu-mlir 同级的目录
# mkdir shufflenet_v2 && cd shufflenet_v2
拷贝测试图片:
# cp -rf ${TPUC_ROOT}/regression/dataset/ILSVRC2012/ .
# cp -rf ${TPUC_ROOT}/regression/image/ .
这里的 ${TPUC_ROOT} 是环境变量,对应 tpu-mlir 目录,是在前面配置 Docker 开发环境中 source ./tpu-mlir/envsetup.sh 这一步加载的
创建名为 export.py 文件,并在文件中写入如下代码:
import torch
from torchvision.models.shufflenetv2 import shufflenet_v2_x1_0
model = shufflenet_v2_x1_0(pretrained=True)
model.eval()
torch.jit.trace(model, torch.randn(1, 3, 640, 640)).save("./shufflenetv2_jit.pt")
运行 export.py 文件:
python export.py
运行成功效果示例
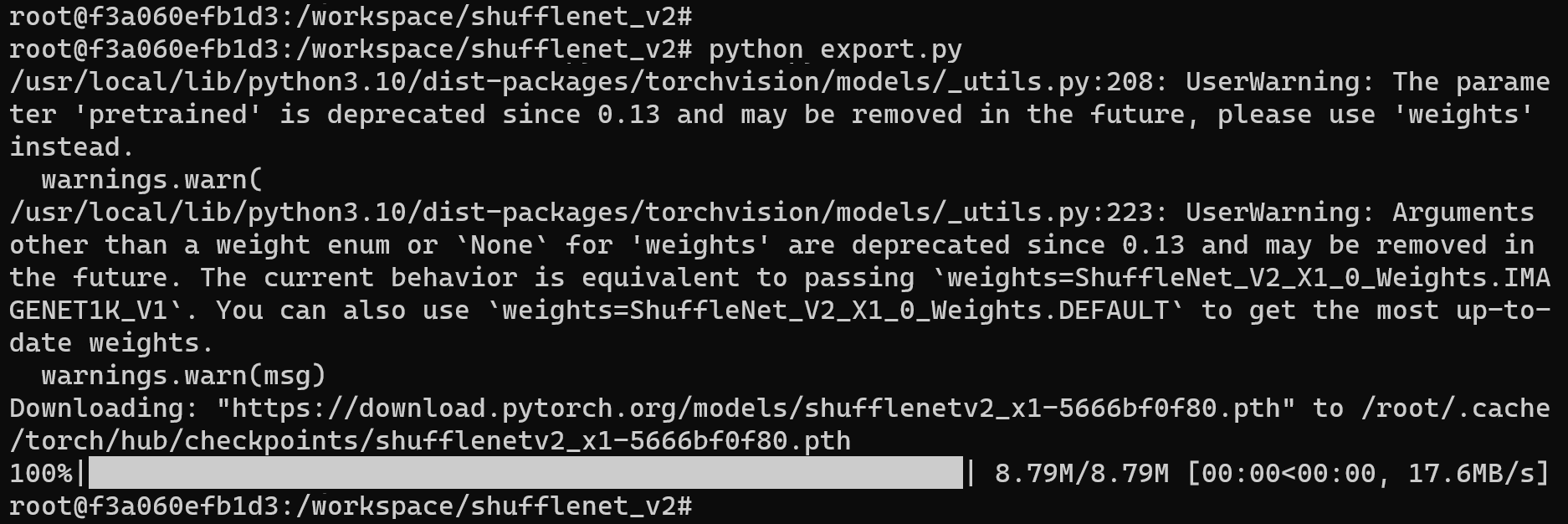
就会在当前目录下生成 shufflenetv2_jit.pt 文件,该文件即为所需的原始模型文件
创建并进入 work 工作目录,用于存放编译生成的 MLIR、cvimodel 等文件
# mkdir work && cd work
3. ShuffleNetV2-PyTorch 模型转换
Duo 开发板搭载的是 CV1800B 芯片,该芯片支持 ONNX 系列 和 Caffe 模型,目前不支持 TFLite 模型。在量化数据类型方面,支持 BF16 格式的量化 和 INT8 格式的非对称量化
模型转换步骤如下:
- PyTorch 模型转换成 MLIR
- 生成量化需要的校准表
- MLIR 量化成 INT8 非对称 cvimodel
PyTorch 模型转换成 MLIR
模型输入是图片,在转模型之前我们需要了解模型的预处理。如果模型用预处理后的 npz 文件做输入,则不需要考虑预处理。预处理过程用公式表达如下($x$代表输入): $$ y = (x-mean)\times scale $$
本例中的模型是 BGR 输入, mean 和 scale 分别为 103.94,116.78,123.68 和 0.017,0.017,0.017,模型转换命令如下:
model_transform.py \
--model_name shufflenet_v2 \
--model_def ../shufflenetv2_jit.pt \
--input_shapes [[1,3,224,224]] \
--resize_dims=256,256 \
--mean 103.94,116.78,123.68 \
--scale 0.017,0.017,0.017 \
--pixel_format bgr \
--test_input ../image/cat.jpg \
--test_result shufflenet_v2_top_outputs.npz \
--mlir shufflenet_v2.mlir
运行成功效果示例
转成 MLIR 模型后,会生成一个 shufflenet_v2.mlir 文件,该文件即为 MLIR 模型文件,还会生成一个 shufflenet_v2_in_f32.npz 文件和一个 shufflenet_v2_top_outputs.npz 文件,是后续转模型的输入文件

MLIR 转 INT8 模型
生成量化需要的校准表
运行 run_calibration.py 得到校准表,输入数据的数量根据情况准备 100~1000 张左右。 这里用现有的 100 张来自 ILSVRC2012 的图片举例,执行 calibration 命令:
run_calibration.py shufflenet_v2.mlir \
--dataset ../ILSVRC2012 \
--input_num 100 \
-o shufflenet_v2_cali_table
运行成功效果示例
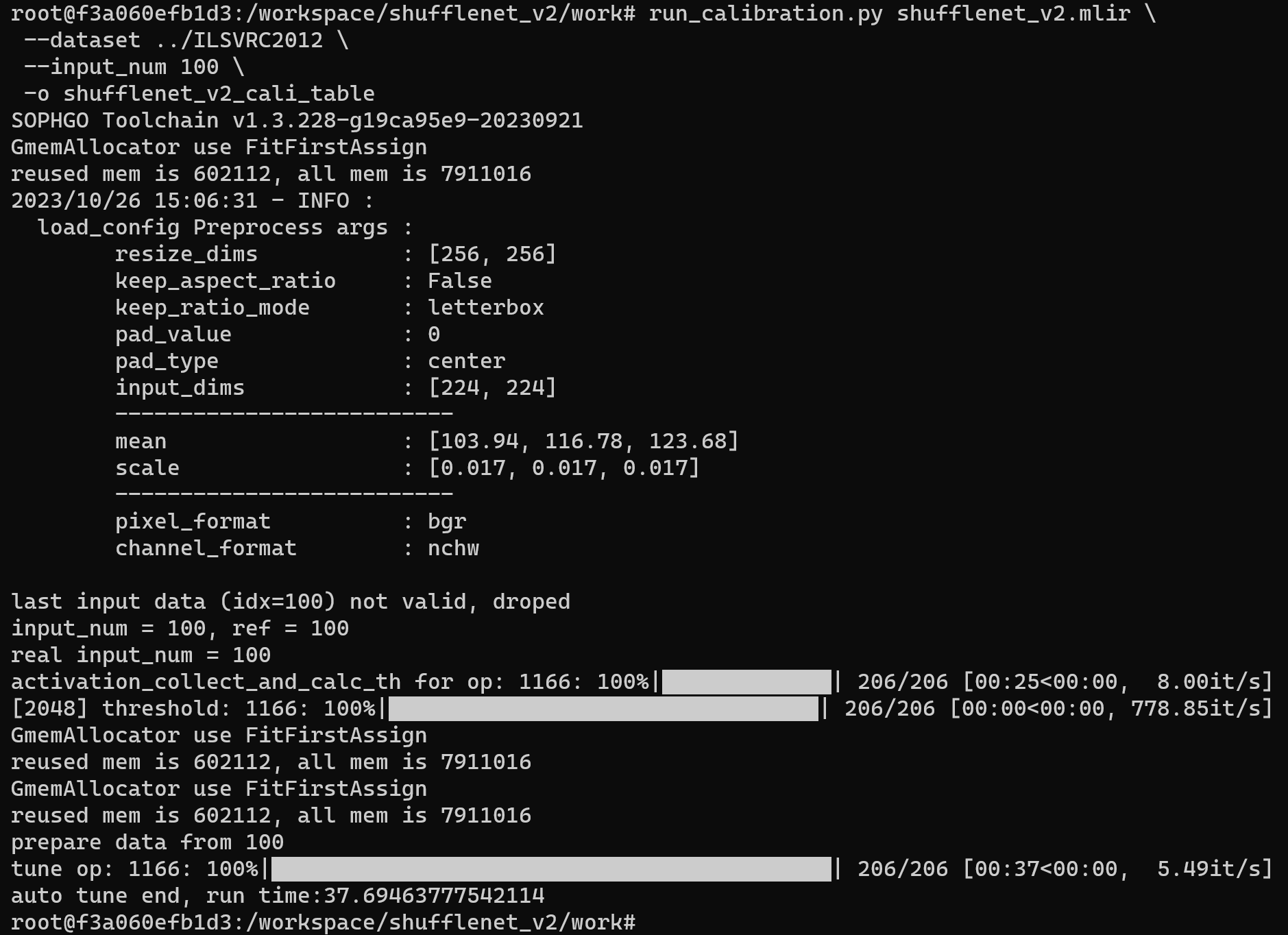
运行完成后会生成名为 shufflenet_v2_cali_table 的文件, 该文件用于后续编译 INT8 模型的输入文件

MLIR 量化成 INT8 非对称 cvimodel
用 model_deploy.py 脚本参数使用 asymmetric 进行非对称量化 将 MLIR 文件转成 INT8 非对称量化模型:
model_deploy.py \
--mlir shufflenet_v2.mlir \
--asymmetric \
--calibration_table shufflenet_v2_cali_table \
--fuse_preprocess \
--customization_format BGR_PLANAR \
--chip cv180x \
--quantize INT8 \
--test_input ../image/cat.jpg \
--tolerance 0.96,0.72 \
--model shufflenet_v2_int8_asym.cvimodel
如果您使用的开发板不是 Duo ,请将上述命令中第 7 行 --chip cv180x 更换为对应的芯片型号。
使用 Duo 256M/Duo S 时应更改为 --chip cv181x。
运行成功效果示例
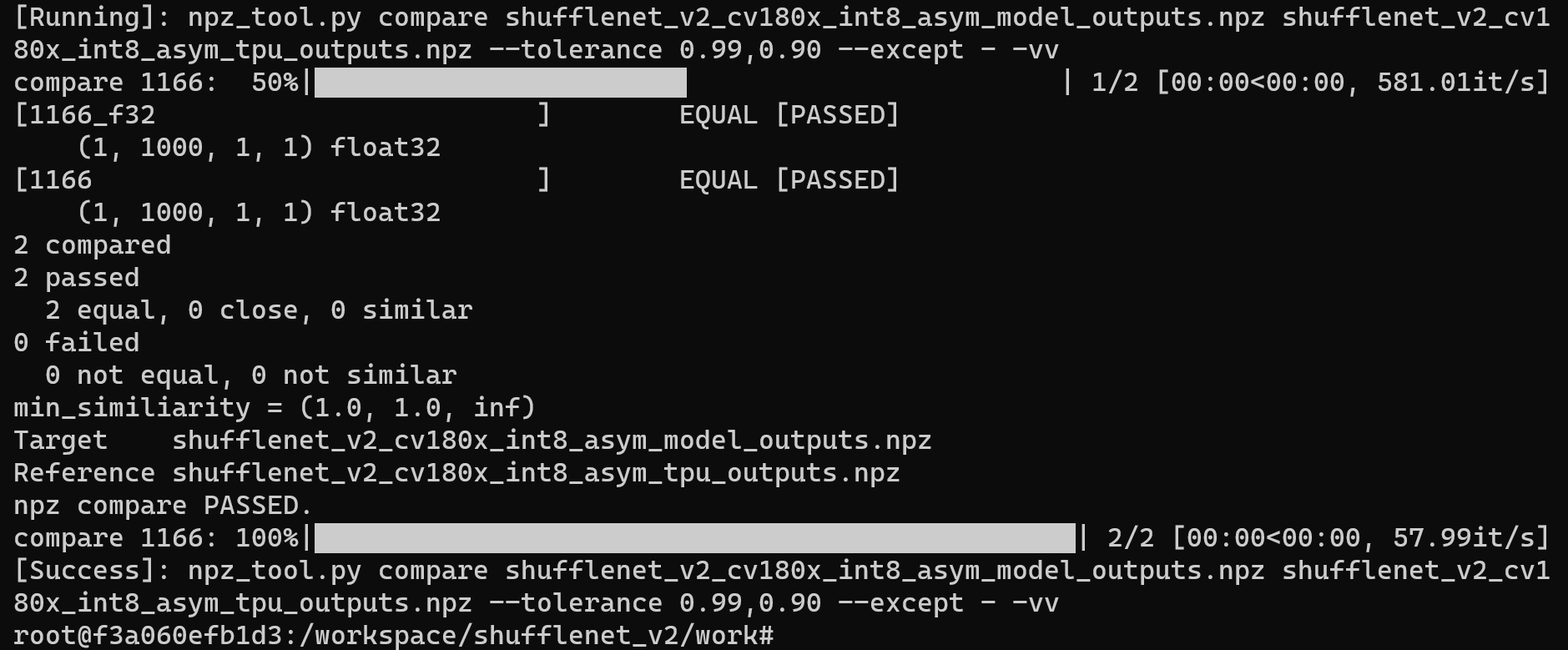
编译完成后, 会生成名为 shufflenet_v2_int8_asym.cvimodel 的文件
4. 在 Duo 开发板上进行验证
连接 Duo 开发板
根据前面的教程完成 Duo 开发板与电脑的连接,并使用 mobaxterm 或 Xshell 等工具开启终端操作 Duo 开发板
获取 tpu-sdk
在 Docker 终端下切换到 /workspace 目录
cd /workspace
下载 tpu-sdk,如果您使用的是 Duo ,则执行
git clone https://github.com/milkv-duo/tpu-sdk-cv180x.git
mv ./tpu-sdk-cv180x ./tpu-sdk
如果您使用的是 Duo 256M/Duo S ,则执行
git clone https://github.com/milkv-duo/tpu-sdk-sg200x.git
mv ./tpu-sdk-sg200x ./tpu-sdk
将开发工具包和模型文件拷贝到 Duo 开发板上
在 duo 开发板的终端中,新建文件目录 /mnt/tpu/
# mkdir -p /mnt/tpu && cd /mnt/tpu
在 Docker 的终端中,将 tpu-sdk 和模型文件拷贝到 Duo 开发板上
# scp -r /workspace/tpu-sdk [email protected]:/mnt/tpu/
# scp /workspace/shufflenet_v2/work/shufflenet_v2_int8_asym.cvimodel [email protected]:/mnt/tpu/tpu-sdk/
设置环境变量
在 Duo 开发板的终端中,进行环境变量的设置
# cd /mnt/tpu/tpu-sdk
# source ./envs_tpu_sdk.sh
进行图像分类测试
在 Duo 开发板上,对该图像进行分类

进入 samples 目录
# cd samples
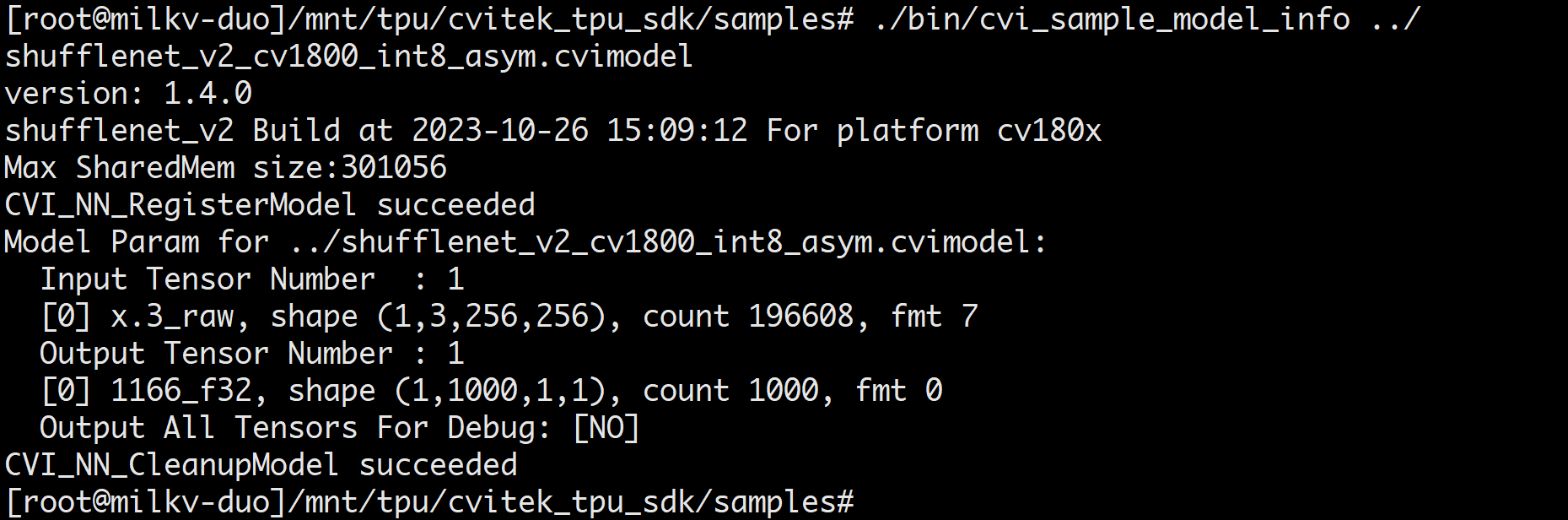
查看 cvimodel info
./bin/cvi_sample_model_info ../shufflenet_v2_int8_asym.cvimodel
运行图像分类测试
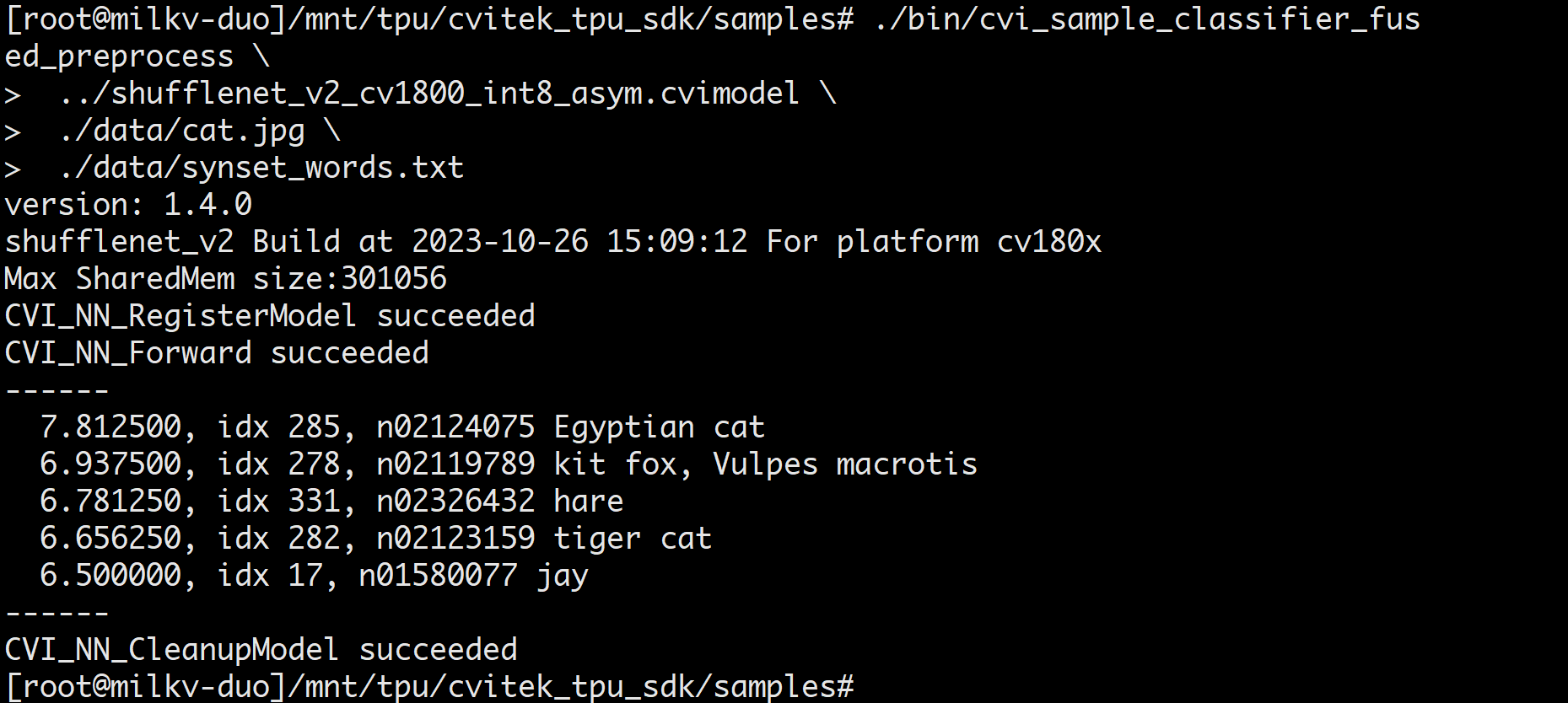
./bin/cvi_sample_classifier_fused_preprocess \
../shufflenet_v2_int8_asym.cvimodel \
./data/cat.jpg \
./data/synset_words.txt
分类成功结果示例